Transformer 注意力机制可视化
这是一个「科研与学术图」类别的 AI 生图提示词案例,风格偏向扁平、极简主义。复制下方完整提示词,打开免费 GPT 生图工具粘贴,即可用 GPT Image-2 免费出图,并可替换主体、品牌名与画幅。
中文完整提示词
生成一张 4:5 竖版「Transformer 注意力机制可视化」案例图,所属分类为「科研与学术图」。Transformer 双头注意力热图,8×8 token 方格,紫色深度编码,语法依存箭头标注,上方 Q/K/V 方块简图。画面需要完整呈现上述主体、构图、配色、材质、光线和整体风格;可见文字以自然简体中文为主,必要的技术缩写、代码、变量名、学术符号、单位、拉丁物种名或装饰性外文可保留。
English full prompt
A minimalist scientific visualization of multi-head self-attention in a transformer model, displayed as an annotated attention heatmap. The heatmap is a square grid (8×8 tokens) where rows represent query tokens and columns represent key tokens; cell color intensity encodes attention weight from white (zero) to deep violet (maximum). Token labels along both axes read: "The", "cat", "sat", "on", "the", "mat", ".", "[EOS]" in 8 pt monospace. Two attention heads are shown side by side: Head 1 heatmap on the left, Head 2 heatmap on the right, each with its own color scale bar below in matching violet-to-white gradient. A thin annotation arrow on Head 1 points to the strong "cat" → "sat" attention cell, labeled "syntactic dependency" in 7 pt sans-serif. Above the heatmaps, a simplified transformer block schematic (Q/K/V rectangles, softmax arrow, output) is shown in flat pale-blue. White background, monochrome violet palette for attention weights.
相关案例
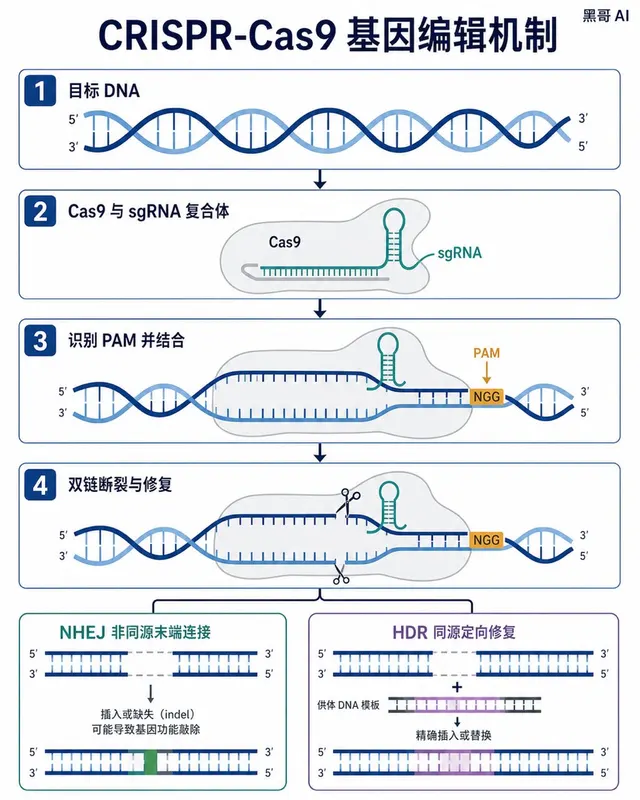
CRISPR-Cas9 基因编辑机制图
生成一张 4:5 竖版「CRISPR-Cas9 基因编辑机制图」案例图,所属分类为「科研与学术图」。四格扁平矢量图,展示 CRISPR-Cas9 切割 DNA 的全过程,深蓝螺旋、灰色 Cas9 蛋白、琥珀色 PAM 位点及红绿结果分支。画面需要完整呈现上述主体、构图、配色、材质、光线和整体风格;可见文字以自然简体中…
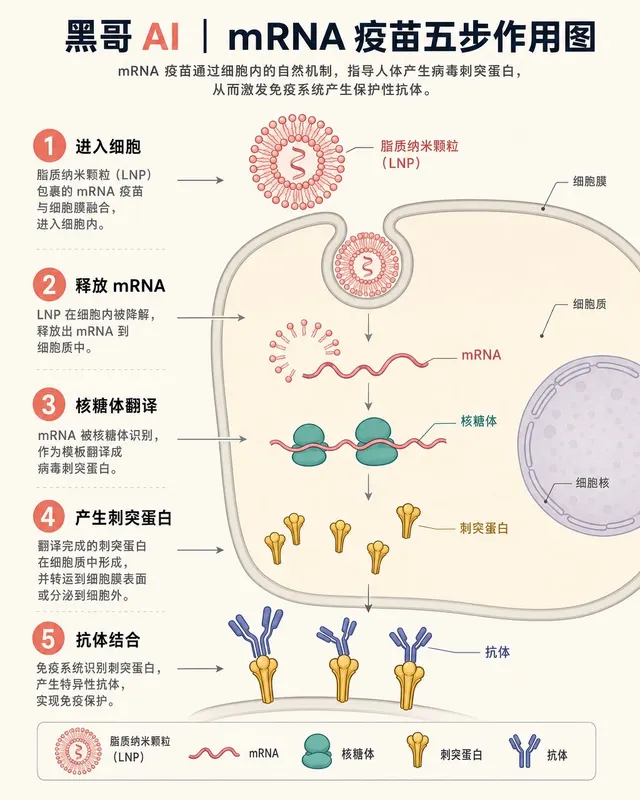
mRNA 疫苗细胞作用机制
一张教科书风格的等距信息图,展示 mRNA 疫苗在人体细胞内的分步作用。背景米白,脂质纳米颗粒(LNP)为珊瑚粉,核糖体为青绿色,刺突蛋白为金色。从 LNP 进入细胞膜,到 mRNA 释放、核糖体翻译刺突蛋白,再到靛蓝 Y 形抗体结合刺突蛋白,共五步,珊瑚色圆形数字徽章标注步骤,细箭头连接,无阴影扁平风格,适合 Sc…
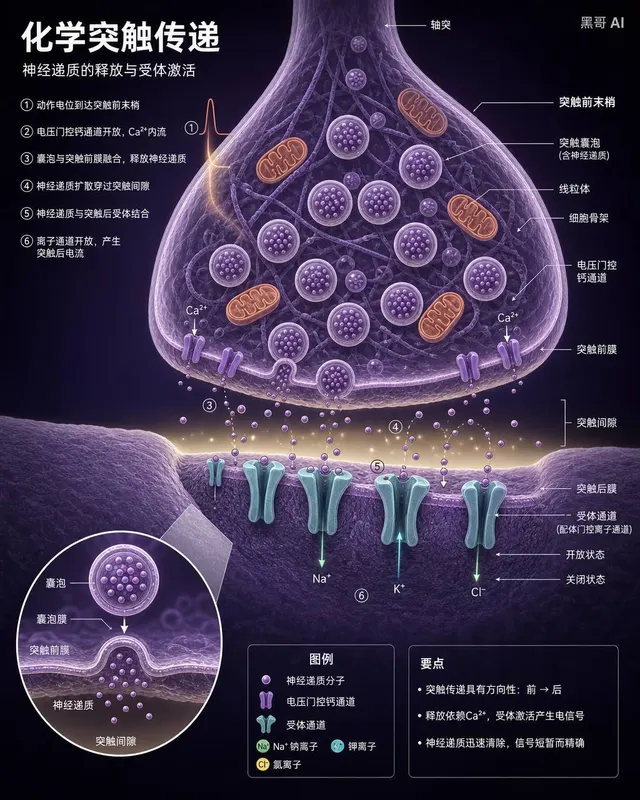
神经突触横截面图
一张高端神经科学教科书风格的化学突触横截面图。上半部为突触前末梢,布满淡紫色囊泡(内含神经递质小点)与暖橙色线粒体;突触间隙为极淡黄色细缝,神经递质分子飞渡其中;下半部突触后膜嵌有青绿色 Y 形受体通道,部分开放部分关闭,标注微小离子流箭头。小圆形插图放大一个囊泡融合事件。深紫背景,细领线标注,9pt Helveti…
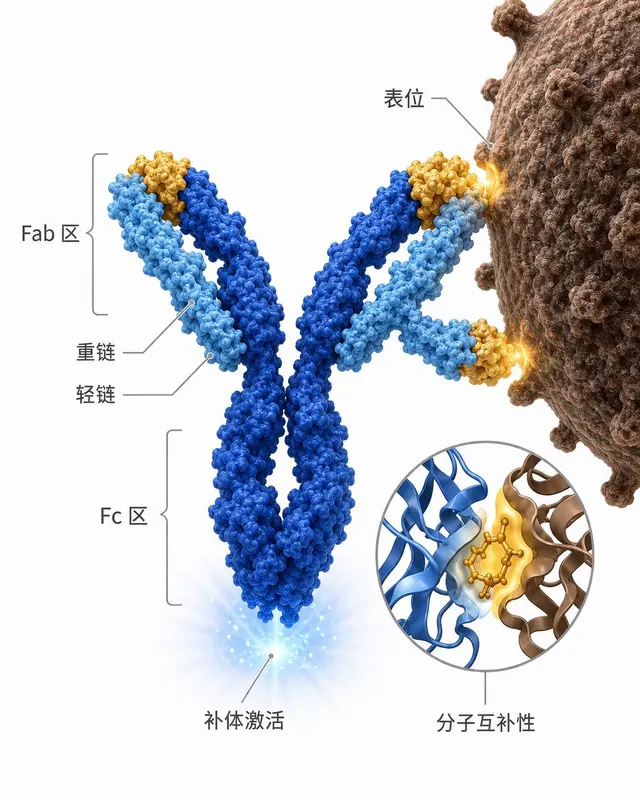
抗体-抗原结合免疫图
一张免疫学讲义风格的 IgG 抗体结合抗原示意图。深钴蓝重链与天蓝轻链构成经典 Y 形,Fab 区末端与病原体(棕褐色粗糙衣壳弧面)上的表位形成锁-钥结合。Fc 区底部微发光暗示补体激活。右下角圆形插图以 ribbon-diagram 风格展示一个结合口袋的分子互补性。白色背景,金色高亮结合区,细灰色领线标注,整洁无…